I'm a little paranoid when it comes to wireless security. Even if I'm on an encrypted wireless network, I won't access any of my bank accounts or login to any website that requires a password without securing my traffic with an additional layer of security using SSH tunneling.
SSH tunneling can also be used to circumvent network-based restrictions in the workplace or on a free public wifi hotspot, giving you the freedom to browse whatever websites you want. If implemented on an OS networking level, you can even use the tunnel for your email and other applications. However the focus of this post is on using SSH tunneling to secure your web traffic.
Here is a quick list of what you'll need:
- Firefox or Internet Explorer (this technique also works with Opera and Safari, although I don't cover those here)
- Putty (Windows); The terminal (Linux or OS X)
- SwitchProxy Tool (nice-to-have Firefox Plugin)
- Access to an *nix-based computer. This will probably be the most difficult to obtain and if you're not familiar with Linux or OS X I recommend you ask a friend if they wouldn't mind giving you an account on their Linux computer. You can try to find a free shell that allows port forwarding, but they are rare.
Setting up the SSH Tunnel
Windows
Since Windows doesn't have an SSH client built in, you will need to use the wonderful SSH client application called Putty. After you've downloaded and launched Putty, you should be presented with the main screen. Fill in the Host Name (or IP address) field with that of your Linux computer and be sure to select SSH from the Connection type.
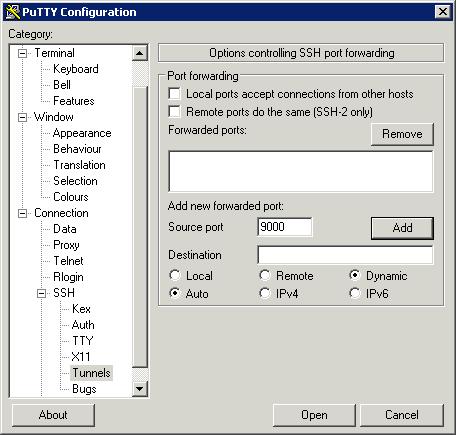
On the left column of options, select Connection -> SSH -> Tunnels. Enter 9000 in the Source port field, select Dynamic from the option at the bottom, and then click Add. Your screen should now look something like this:
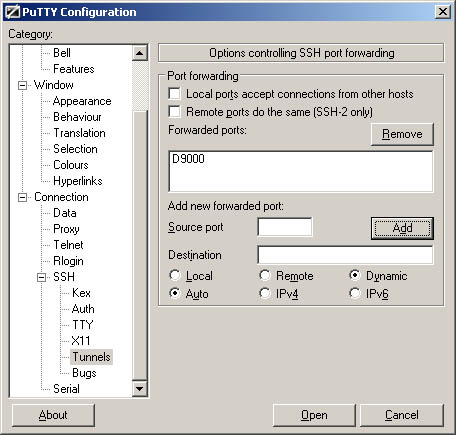
Note: If you don't see the Dynamic option in Putty, make sure you have the latest version.
Now go ahead and click the Open button to connect to and login to your Linux computer. Once you have successfully logged in, the tunnel will be open and you can proceed to configure your web browser to use the tunnel.
Linux/OS X
Since you're using a *nix based system, your computer already has everything it needs to setup an SSH tunnel. Simply access the terminal (Applications -> Utilities -> Terminal.app on OS X) and connect to the remote Linux computer as follows:
ssh -l -D 9000
After logging into the remote computer, the dynamic SSH tunnel will be opened and we can continue to configuring the web browser.
Configuring the Web Browser to use the SSH Tunnel
Firefox with SwitchProxy Tool plugin (the method I use)
Download and install the SwitchProxy Tool plugin. After installing the plugin, open its configuration window (Tools -> Add-ons -> SwitchProxy Tool -> Preferences on OS X). This will open the basic configuration window for the plugin. Click Manage Proxies and then Add. Choose Standard for the proxy configuration type and click Next. Fill in the fields as shown below.
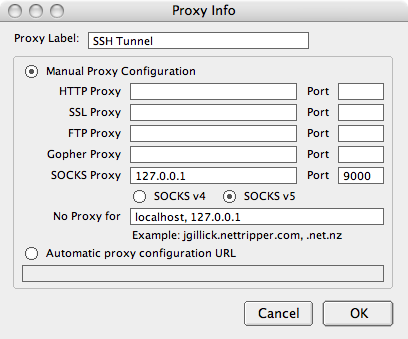
After saving the connection, you should be able to use the plugin to easily switch between browsing through the SSH tunnel and browsing without it. I have it configured to show in the Firefox Status Bar, as I find that to be the easiest method of toggling between the two:
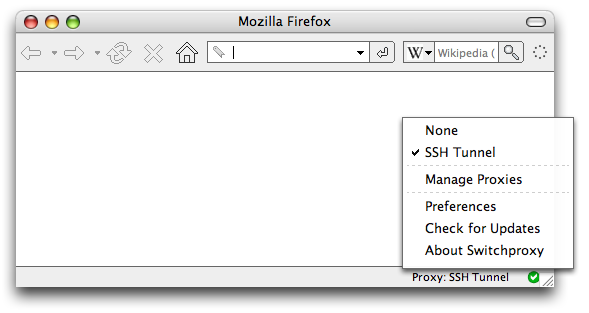
Firefox without SwitchProxy Tool
Although SwitchProxy Tool to easily switch my proxy settings, I will also explain how to configure the browser without the plugin.
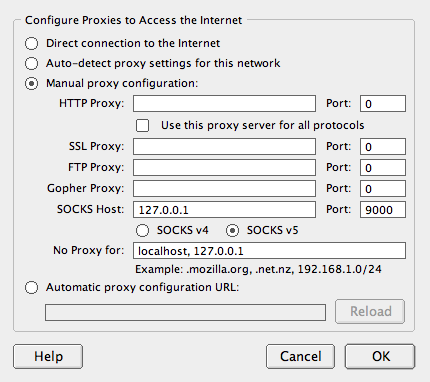
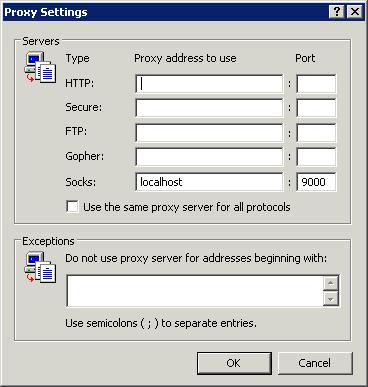
Open the Firefox Preferences (Firefox -> Preferences on OS X) and click the Advanced icon at the top. In the connection section, click the Settings... button. Choose Manual proxy configuration and fill in the SOCKS Host and Port fields as shown below.
Internet Explorer
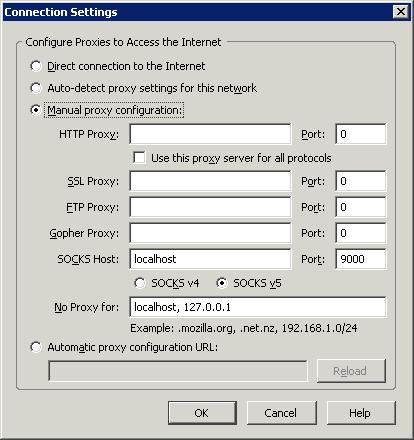
From the Internet Explorer menu, choose Tools -> Internet Options. Select the Connections tab and then click the LAN Settings button. Enable the Use proxy server for your LAN option and click Advanced.
In the Servers section, make sure all the fields are empty except for the Socks field. Type localhost in the Socks Proxy address field and 9000 in the Port field. Your screen should look something like this:
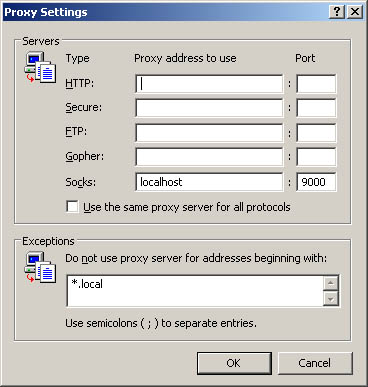
Click the OK button all the way back to your browser. You should now be browsing the Internet securely through the SSH tunnel! An easy way to confirm this is to disconnect from the Linux computer by closing Putty and checking if you can still browse the web. Since the browser has been configured to use the tunnel, you won't be able to browse the web if that tunnel is closed.
If you wish to revert back to browsing the web normally, simply uncheck the Use proxy server for your LAN option in LAN Settings.