
Programming
There are 48 posts tagged Programming (this is page 2 of 3).
Amazon S3 HMAC Signatures without PEAR or PHP5
The Amazon S3 proposal for uploading via POST describes how to assemble a policy document that can be used to create a time-sensitive signature. The obvious advantage to this method is that you don't have to worry about someone stealing your secret AWS key or uploading random files without your permission.
Here is the example policy document from the proposal:
{ "expiration": "2007-12-01T12:00:00.000Z", "conditions": [ {"acl": "public-read" }, {"bucket": "johnsmith" }, ["starts-with", "$key", "user/eric/"], ["content-length-range", 2048, 20971520] ] }This Policy document is Base64 encoded and the Signature is the HMAC of the Base64 encoding.
The application I am developing at work requires this signed policy method of uploading files to S3, however I needed to do it with PHP4 and preferably without any extra PEAR packages. This posed somewhat of a challenge, as all the tutorials I found on the web explained how to sign the policy using the PEAR Crypt_HMAC package or some feature of PHP5.
I eventually figured it out, and I'm here to show you how. The two functions used were found on the web (I don't remember exactly where) and worked perfectly for my situation.
(Note: I had a lot of trouble saving the contents of the following code in WordPress due to some Apache mod_security settings configured on my server.)
/*
* Calculate HMAC-SHA1 according to RFC2104
* See http://www.faqs.org/rfcs/rfc2104.html
*/
function hmacsha1($key,$data) {
$blocksize=64;
$hashfunc='sha1';
if (strlen($key)>$blocksize)
$key=pack('H*', $hashfunc($key));
$key=str_pad($key,$blocksize,chr(0x00));
$ipad=str_repeat(chr(0x36),$blocksize);
$opad=str_repeat(chr(0x5c),$blocksize);
$hmac = pack(
'H*',$hashfunc(
($key^$opad).pack(
'H*',$hashfunc(
($key^$ipad).$data
)
)
)
);
return bin2hex($hmac);
}
/*
* Used to encode a field for Amazon Auth
* (taken from the Amazon S3 PHP example library)
*/
function hex2b64($str)
{
$raw = '';
for ($i=0; $i < strlen($str); $i+=2)
{
$raw .= chr(hexdec(substr($str, $i, 2)));
}
return base64_encode($raw);
}
/* Create the Amazon S3 Policy that needs to be signed */
$policy = '{ "expiration": "2007-12-01T12:00:00.000Z",
"conditions": [
{"acl": "public-read" },
{"bucket": "johnsmith" },
["starts-with", "$key", "user/eric/"],
["content-length-range", 2048, 20971520]
]';
/*
* Base64 encode the Policy Document and then
* create HMAC SHA-1 signature of the base64 encoded policy
* using the secret key. Finally, encode it for Amazon Authentication.
*/
$base64_policy = base64_encode($policy);
$signature = hex2b64(hmacsha1($secretkey, $base64_policy));
That's it! This method doesn't require PHP5 and doesn't require any additional PEAR packages.
s3delmany.sh – Delete Many S3 Objects With One Command
Update: The Amazon S3 service API now allows for deleting multiple objects with one request (up to 1,000 objects per request). Please see the Amazon S3 Developer Guide for more information.
I've been doing some stuff at work using Amazon S3 to store files and during my testing I uploaded a ton of files that didn't need to be there. Unfortunately, the command line tool I'm using, s3cmd, does not allow me to delete multiple files at once. There is no way to do a wild-card delete. This means I would need to get the full path to each object and delete them one by one:
./s3cmd del s3://s3.ekarma.net/img/1205794432gosD.jpg
Object s3://s3.ekarma.net/img/1205794432gosD.jpg deleted
./s3cmd del s3://s3.ekarma.net/img/1205794432g34fjd.jpg
Object s3://s3.ekarma.net/img/1205794432g34fjd.jpg deleted
Yea, there's no way I'm doing that for over 200 objects. I mean come on, there are tools to automate this kind of stuff! So I created s3delmany.sh:
#!/bin/sh
# -------------------------
# s3delmany.sh
# Author: Raam Dev
#
# Accepts a list of S3 objects, strips everything
# except the column containing the objects,
# and runs the delete command on each object.
# -------------------------
# Redirect output to the screen
2>&1
# If not using s3cmd, change this to the delete command
DELCMD="./s3cmd del"
# If not using s3cmd, change $4 to match the column number
# that contains the full URL to the file.
# This basically strips the rest of the junk out so
# we end up with a list of S3 objects.
DLIST=`awk 'BEGIN { print "" } { print $4, "t"} END { print ""}'`
# Now that we have a list of objects,
# we can delete each one by running the delete command.
for i in "$DLIST"; do $DELCMD $i
done
Download
s3delmany.zip
Installation
1. Extract s3delmany.zip (you can put it wherever, but I put it in the same directory as s3cmd).
2. Edit it with a text editor and make sure DELCMD is set correctly. If you're not using s3cmd, change it to match the delete object command for that tool.
3. Make it executable: chmod 755 s3delmany.sh
Usage
If you're using s3cmd and you placed s3delmany.sh in the /s3cmd/ directory, you should be able to use the script without modifying it. The script works by taking a list of objects and running the delete command on each one.
To pass s3delmany.sh a list of objects, you can run a command like this:
./s3cmd ls s3://s3.ekarma.net/img/ | ./s3delmany.sh
This will delete all objects under /img/. Make sure you know the output of your s3cmd ls command before you pass it to s3delmany.sh! There is no prompt asking if you're sure you want to delete the list, so get it right the first time!
Hint: s3cmd doesn't allow you do use wild-cards, but when you run the ls command, you can specify the beginning of an object name and it will only return objects starting with that. For example, s3cmd ls s3://s3.ekarma.net/img/DSC_, will return only those objects that begin with DSC_.
Alternate Usage
If you have a text file containing a list of S3 objects that you want to delete, you can simply change print $4 to print $1 and then do something like this:
cat list.txt | ./s3delmany.sh
By the way, print $4 simply tells s3delmany.sh that the S3 objects are in the 4th column of the data passed to it. The ./s3cmd ls command outputs a list and the object names are in the 4th column. The awk command expects the columns to be separated by tabs (t).
If you have any questions or comments, please don't hesitate to use the comment form below!
ERROR 406: Not Acceptable
The other day I was writing a script for work and discovered it wasn't behaving as expected. The web browser didn't give me any helpful information so I decided to use wget to see what the actual error was:
eris:~ raam$ wget --spider -v mysite.com
Connecting to mysite.com|69.16.69.151|:80... connected.
HTTP request sent, awaiting response... 406 Not Acceptable
16:19:28 ERROR 406: Not Acceptable.
Ah ha! ERROR 406: Not Acceptable. After doing some Googling I discovered the problem is related to an optional (though commonly installed) Apache module called mod_security. This module basically acts as a firewall for Apache to help prevent website attacks, specifically attacks through POST submissions.
To disable mod_security, you can place the following line in an .htaccess file on the root of your site:
SecFilterEngine off
I then confirmed that disabling mod_security actually fixed the problem:
eris:~ raam$ wget --spider -v mysite.com
Connecting to mysite.com|69.16.69.151|:80... connected.
HTTP request sent, awaiting response... 200 OK
So as you can see, the quick solution to fixing the Error 406 problem is to disable mod_security altogether using a .htaccess file. However, this leaves me wondering how much security I'm giving up by disabling mod_security.
I was in a hurry when this happened so I didn't spend much time investigating what exactly my script was doing that may have caused mod_security to freak out. Sometimes other applications cause the Error 406 problem, such as WordPress or Mambo, and you really don't have choice except to wait for a fix to be released. Since my own software caused the problem, figuring out why should be easy. I'll post my results when I determine what was.
Subversion on Mac OS X
My workplace is switching from CVS to Subversion for source-code version control so I need to pick up Subversion rather quickly. It took me awhile to get comfortable developing with CVS and now I need to learn stuff all over again. I even have scripts setup to help with the deployment of my project using CVS -- now they need to be modified to work with Subversion. Oh well, I'm sure its for the best.
I've been reading the awesome, and free, Subversion book a lot lately and it has really helped with my understanding of how Subversion works. Since Subversion is not installed on OS X by default, we need to install it before using it from the command line. I downloaded the easy-to-install Subversion .dmg distributed by Martin Ott.
After running the .pkg-installer I was able to run svn help from the command line to confirm it was installed properly. If that command doesn't work after installing, you may need to add this line to the .profile file (in your home directory):
export PATH=$PATH:/usr/local/bin
Now you should be able to run all the SVN commands from your Mac OS X command line. If you prefer a GUI interface to SVN, check out svnX. I do all my development from within Eclipse, so I'm using an SVN plugin for Eclipse called Subversive. I prefer it over the more commonly known Subeclipse plugin because Subversive has a friendlier, and seemingly more configurable, interface.
Checking out a project from the command line over SSH is really simple, however while searching Google I was unable to find this "simple" answer. If I had found the free Subversion book before searching for this answer, I probably wouldn't be writing this:
svn checkout svn+ssh://svn.dev82.org/projects/myproject
That's it! The syntax for checking out a project is very similar to CVS, however SVN has the concept of "URLs" to specify the location and type of connection to your repository. If you have SSH Client Keys setup, you can run SVN commands over SSH without the password prompt (which is necessary for the deployment scripts I use).
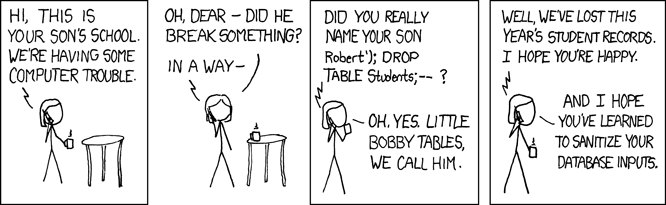
Sanitize your Database Input!
I don't like posting comics, but today's xkcd really hit home. As a web developer, I constantly need to worry about sanitizing SQL input to avoid security holes in my software.
Comment History with Get Recent Comments Plugin
My Dad and I have been going back and forth quite a bit in the comments on a recent post I wrote about Consumption. This filled up the Recent Comments list on the sidebar rather quickly and I wasn't able to see other recent comments. I realized a comment history or archive page, similar to my post archive page, would be very useful.
After looking around a bit, I found a really nice plugin by Krischan Jodies called Get Recent Comments. It has a ton of features and lots of configuration options. It has been updated as recently as last month and even supports the new widgets feature of WordPress 2.3 (it also works with older versions of WordPress as far back as 1.5).
By default, the instructions included with the plugin explain how to add recent comments to your sidebar. They don't, however, mention anything about creating a comment history page. In the instructions there is a snippet of PHP code which you are supposed to use in the sidebar.php file of your WordPress template. I thought great, I simply need to create a new page in WordPress and add that snippet of code to the page using the runPHP plugin to execute the PHP on that page. This worked, partially. At the top of my comment history was this error:
Parse error: syntax error, unexpected $end in /home/raamdev/public_html/blog/wp-content/plugins/runPHP/runPHP.php(410) : eval()’d code on line 1
I thought perhaps it was because my runPHP plugin was outdated, so I upgraded it to the latest version (currently v3.2.1). I still received the error, so I decided to play around with the snippet of PHP code provided by the Get Recent Comments plugin. I was able to modify it slightly to get rid of the error as well as output some additional text. Here is the snippet of code I use to create my new Comment History page:
<?php
if (function_exists('get_recent_comments')) {
echo "(Showing 500 most recent comments.)";
echo "<li><ul>". get_recent_comments() ."</ul></li>";
}
?>
In the plugin options, I configured the plugin to group recent comments by post. This created a very readable Comment History page. After adding the ID of the new page to the exclude list in my header.php file to prevent the page from showing in the header (wp_list_pages('exclude=704&title_li=' )), I added a 'View comment history' link to the bottom of the Recent Comments list on the sidebar.
The Get Recent Comments plugin is really powerful and I'm a bit surprised that the plugin doesn't include basic instructions about how to create a comment history page. If you receive a decent amount of feedback from your visitors (in the form of comments), this is a great way to see all that feedback on a single page. If you have Trackback's and Pings enabled, this plugin can even show those.
Using wget to run a PHP script
wget is usually used to download a file or web page via HTTP, so by default running the wget http://www.example.com/myscript.php would simply create a local file called myscript.php and it would contain the contents of the script output. But I don't want that -- I want to execute the script and optionally redirect its output somewhere else (to a log file or into an email for reporting purposes). So here is how it's done:
$ wget -O - -q http://www.example.com/myscript.php >> log.txt
According to the wget man page, the "-O -" option is used to prevent wget from saving the file locally and instead simply outputs the result of the request. Also, wget normally produces it's own output (a progress bar showing the status of the download and some other verbose information) but we don't care about that stuff so we turn it off with the "-q" option. Lastly, the ">> log.txt" redirects the output of the script to a local file called log.txt. This could also be a pipe command to send the output as an email.
There is an incredible amount of power behind wget and there are a lot of cool things you can use it for besides calling PHP scripts from the command line. Check out this LifeHacker article for a bunch of cool uses.
How I started programming
I learned about programming when I was 12, three years after I began building computers. I asked my Dad one day (at the time he was working at Digital as a technical writer) how the games and programs on the computer were created. He didn't know a whole lot about programming, but he knew of the BASIC programming language and told me I should get a book and learn it. So I bought a book and started using QBASIC on MS-DOS 6.22. From there I moved to Visual Basic (which I later realized was a big mistake). VB was very much like BASIC and making the transition was very easy. I coded "AOL apps" for awhile (for those who remember: Punters, Mail Bombs, ChatRoom Busters, etc.) until AOL started cracking down on such things.
A few years later, when programming for money came into view, I discovered that I should really be familiar with C or C++. So I glanced through a couple of C programming books and wow, what a difference from BASIC! My mental understanding of how programming languages worked had been spoiled by the simplistic syntax of BASIC and VB. It took many, many books to finally get a basic understanding of C and C++. I also flipped through a couple of Java books around this time because I heard the syntax was similar to C. Besides, who wouldn't want to learn a programming language called Java?
HTML is something I have almost always known how to use (I can't even remember when I first learned it) and I never really thought of it as a programming language. When I started to realize how important, and powerful, dynamic web applications were becoming, I decided to investigate what it was that made the HTML dynamic (after all, if you view the source of a dynamic web page, it usually just looks like plain HTML!). I discovered, almost accidentally, the open-source programming language PHP (PHP: Hypertext Preprocessor) and quickly started learning it. I later learned about ASP (Microsoft's Active Server Pages) and JSP (JavaServer Pages) (wow, am I glad I found PHP first!). Since then I have also learned a lot about databases, including database design and the basic principles of good database design. The most popular database used with PHP at the time was MySQL, so that is what I studied. I've also had some light exposure to MSSQL.
Currently, I am working at a software startup company called Aerva, Inc. in Cambridge, Massachusetts doing everything from software support and debugging to being the "company muscle" (I'm the only one with a truck). I have built, and currently manage, their Support Center using PHP & MySQL, although I have also had to write some bash and Perl (ugh!) scripts to interface with their software provisioning process. I continue to work on adding new features to the Support Center to help streamline regular processes while at the same time increasing my knowledge of various programming languages and the Linux operating system.
I code with PHP on a daily basis (on a MacBook Pro using MAMP and Eclipse) and I am currently working on several of my own web projects. I just finished working on a little application called ASAP - Automated Staging and Publishing, which allows me to automate the process of checking out a project from CVS and then rsync'ing it to a remote server for staging or publishing purposes.
Everyone says PHP is "easy" to learn, and although they are probably right they fail to realize that its simplicity is also its weakness. To code good and secure PHP you need to have a strong understanding of the language and how best to use its many features. In addition to continuing to perfect my understanding of the PHP programming language and related OOP (Object-Oriented Programming) technologies, I wish to learn more about Java, XML, and AJAX.
phpBB photo-captcha image loading issues
A friend was having trouble with the photo-captcha mod he installed in phpBB. The photo-captcha mod basically presents users with a group of images and asks them to choose all images that fit a certain category (i.e., choose all cars). After installing the mod however (and fixing a couple of silly mistakes), only half of the images would show up. And it wasn't the same images not showing up, it was entirely random.
As is usually the case with debugging, I looked for a working example with which I could compare the non-working one. When I found a working photo-captcha mod, I noticed the images loaded more slowly and consistently than on the non-working example. It was as if the non-working example was on crack, while the working example was practicing yoga.
I compared HTTP headers, checked cache settings, and everything else I could think of, but nothing looked out of the ordinary. So I decided to try something. Why not force the mod to pause between loading each image?
So I opened /forum/includes/usercp_confirm.php and modified it:
$image = $sub;
@imagegammacorrect($image, 1.0, (0.5 + mt_rand(0,1200)*0.001));
header('Content-Type: image/jpg');
header('Cache-control: no-cache, no-store');
@imagepng($image);
// -------- EDIT BY RAAM --------
sleep(1);
// -------- END EDIT ---------
exit;
And it worked! The code paused for 1 second between loading each image and all the images loaded properly. I have no idea what caused this problem but if you know please leave a comment! And if you're having this same issue, at least now you have a solution. 🙂
NoteSake.com beat me to the punchline
For the past two years or so, I've been slowly working on a website called SaveNotes.com. However, while reading LifeHacker I came across a site called NoteSake.com. Apparently, they beat me to the punchline.
Their site looks great and has very similar features as what I had planned for SaveNotes.com. There are a couple of things I planned on doing differently, such as the ability to quickly create a note without logging in or authenticating yourself, but there were a lot of things I hadn't even thought of, such as the ability to export notes as a PDF or share notes with other NoteSake users.
I tried creating an account on NoteSake.com to try out the features, however I'm still waiting for the email that contains the confirmation URL (which is another reason I disliked the idea of requiring an account).
Perhaps I will continue to develop SaveNotes.com simply because it would be a tool I would find very useful. Besides, NoteSake.com doesn't really have any competition. Yet. 🙂
ImgListGenerator
Introduction
I've been doing a lot of eBay auctions lately and one of the most time consuming parts was creating the HTML for all the images in my auction description. I could reuse a lot the HTML, simply changing the directory and image names, but it was still a lot of repetitive work. This week I had 25 items to list and the repetitive work really got to me, so I stopped and spent 30 minutes putting together a script that would help me.
Usage
To simplify things, I decided not to support the ability to choose the directory with the images for which you want to generate HTML. Instead, you simply upload the index.php file to the directory that contains your images, visit that directory with your web browser, and the HTML is generated. Since your web browser reads HTML, the images will be displayed just as they would in your eBay auction. Simply right click on the page, choose View Source, copy the nicely formatted HTML and paste it into your eBay description.
You can view this script in action by browsing some of my images here.
Details
Here's a sample output from this script:
<p align="center"><img src="http://www.ekarma.net/demo/pics/sample/DSC_0001.jpg"></p> <p align="center"><img src="http://www.ekarma.net/demo/pics/sample/DSC_0003.jpg"></p> <p align="center"><img src="http://www.ekarma.net/demo/pics/sample/DSC_0004.JPG"></p> <p align="center"><img src="http://www.ekarma.net/demo/pics/sample/DSC_0010.JPG"></p>
The code I had to write for this script was rather simple. The real meat of the work is done by a very nice function called preg_find() by Paul Gregg. His code is too much to show here, but I'll show you the code I wrote for this little script:
// Find all .jpg or .JPG files in the current directory using preg_find()
$files = preg_find('/.jpg|.JPG/', '.', PREG_FIND_SORTBASENAME);
// Store the path to the current directory
// (PHP_SELF includes index.php, so we use substr to remove that)
$link_dir = substr($_SERVER['PHP_SELF'], 0, -9);
// Loop through each of the files and generate the HTML
foreach($files as $file){
$my_file = substr($file, 2, strlen($file));
echo "<p align="center"><img src="http://" /></p>\n";
}
That's it! Of course it would be much nicer if you could upload this script to the root directory and either enter or choose a path with images, then click generate. However, this script does exactly what I need, so I don't plan to make any changes to it.
Download
This script can be downloaded here: index.php.zip (4KB)
Using rsync to Mirror two CVS Repositories
I have two personal Linux servers, named Mercury (located in Lowell, MA) and Pluto (located in Cambridge, MA). Monday through Friday I stay in my Cambridge apartment to be close to work and on the weekends I go back to Lowell.
I've been storing all of my projects, both work and personal, in a CVS repository on Mercury. A few weeks ago, however, there was a power outage in Lowell during the middle of the week and Mercury didn't turn back on (probably because I don't have the "PWRON After PWR-Fail" BIOS option set to Former-STS, if it even has that option). So, since the computer wasn't on, I wasn't able to commit or sync any of the projects I was working on. This would normally not be a problem, however I have several staging scripts setup on Mercury which I use frequently to test my work -- so basically I was dead in the water.
After this incident, I realized I needed to mirror my CVS repository to prevent anything like that from happening again. This mirror would not only allow me to access the same CVS repository in the event that I was unable to reach one of my servers, but it would also act as a backup in case I somehow lost all the data on one of the servers.
After a little research using Google, I found this site which basically explains the -a option for rsync:
By far the most useful option is -a (--archive). This acts like the corresponding option to cp; rsync will:
* recurse subdirectories (-r);
* recreate soft links (-l);
* preserve permissions (-p);
* preserve timestamps (-t);
* attempt to copy devices (if invoked as root) (-D);
* preserve group information (-g) (and userid, if invoked as root) (-o).
Using that info, I ran the following command from Mercury (l.rd82.net is the DNS address I have mapped to it's public IP, and c.rd82.net is mapped to Pluto's public IP)
rsync -a /home/cvs raam@c.rd82.net:/home
That's it! After waiting a few minutes (it took several minutes the first time) my entire CVS repository was copied to Pluto, my Cambridge Linux server. Of course, before I ran that command I had to create the CVS repository on Pluto first by running cvs init /home/cvs. After the rsync command completed, I added a CVS repository for c.rd82.net in Eclipse and confirmed that all my projects were there.
The only thing left to do is to setup a cron job to run the command every night. Of course, I'll need to setup SSH keys so the rsync command can run without user input, but thats easy.
Removing unwanted commas in a CSV file with PHP
During the past week, I've been working on a small PHP application that a friend paid me to write, called SearchCSV2MySQL. He is exporting data from a specific program and saving the data in Excel as *.csv. Here is what a sample of the data looks like:
130072690978,Jan-31 09:09,4.95,$,1,Vintage McMurdo SILVER Television Pre-Amplifier
220073351918,Jan-25 19:48,"1,031.00",$,2,"PITNEY BOWES, TABLETOP INSERTING MAILING SYSTEM"
As you might have guessed, you're looking at eBay auction information. The fields in the exported data are item, date, price, currency, bid count, and description. Importing large amounts of CSV data into a MySQL database is one thing (and I'll write a follow up post detailing how the application works), but I also needed to remove unwanted fields before importing the data into MySQL.
To do this, I break up each line using $fields = explode(",", $lines[$y]);, where $y is the current line we're processing. This takes the data between the commas and puts it into the $fields array. However if you look at the sample exported data carefully, you may realize that we won't get the results we're expecting. The commas found between the double quotes, in the price and description fields, will be processed as field separators! This would cause $fields[2] (the price field) for the second line to contain "1" instead of "1,031.00".
So how did I resolve this? After looking over the syntax for strpos(), substr(), and substr_replace() a million times, I finally came up with this solution:
/*
* ***************** Remove all commas from the price field ******************
*/
/* Isolate the second field (price field) by finding the position
* of the comma right before the price field (second comma)
*/
$first_comma_pos = strpos($lines[$y], ",");
$second_comma_pos = strpos($lines[$y], ",", $first_comma_pos + 1);
/* Check if the price field contains double quotes,
* which would mean the price has a comma in it and we need to remove it
*/
if(substr($lines[$y], $second_comma_pos + 1, 1) == """){
/* Find the positions of the opening and closing double quotes around the price */
$price_quotes_pos_start = strpos($lines[$y], """);
$price_quotes_pos_end = strpos($lines[$y], """, $price_quotes_pos_start + 1);
/* Find all occurences of a comma after the opening double quote, but before the closing quote,
* around the price field and remove them from this line.
*/
$price_comma_pos = strpos($lines[$y], ",", $price_quotes_pos_start);
while($price_comma_pos < $price_quotes_pos_end){
$lines[$y] = substr_replace($lines[$y], "", $price_comma_pos, 1);
$price_comma_pos = strpos($lines[$y], ",", $price_quotes_pos_start);
/* Update the position of $price_quotes_pos_end,
* since it has changed after we removed a comma!
*/
$price_quotes_pos_end = strpos($lines[$y], """, $price_quotes_pos_start + 1);
}
}
/*
* ***************** Remove all commas from the description field ******************
*/
/* Find the position of the comma right before the description field (fourth comma) */
$first_comma_pos = strpos($lines[$y], ",");
$second_comma_pos = strpos($lines[$y], ",", $first_comma_pos + 1);
$third_comma_pos = strpos($lines[$y], ",", $second_comma_pos + 1);
$fourth_comma_pos = strpos($lines[$y], ",", $third_comma_pos + 1);
$fifth_comma_pos = strpos($lines[$y], ",", $fourth_comma_pos + 1);
/* Check if the description field contains double quotes,
* which would mean the description has a comma in it and we need to remove it
*/
if(substr($lines[$y], $fifth_comma_pos + 1, 1) == """){
/* Find the positions of the opening and closing double quotes around the description */
$desc_quotes_pos_start = strpos($lines[$y], """, $fifth_comma_pos);
$desc_quotes_pos_end = strpos($lines[$y], """, $desc_quotes_pos_start + 1);
/* Find all occurences of a comma after the opening double quote, but before the closing quote,
* around the description field and remove them from this line.
* Since this is the last field, we dont need to worry about finding any
* commas after the closing quote, and therefore don't need to update $desc_quotes_pos_end.
*/
while($desc_comma_pos = strpos($lines[$y], ",", $desc_quotes_pos_start)){
$lines[$y] = substr_replace($lines[$y], "", $desc_comma_pos, 1);
}
}
I realize that there are a couple of limitations to this code, such as not removing both commas if the price contains a larger number (i.e., "1,042,240.00"). It also doesn't look in the description field for commas. UPDATE: I've updated the code to remove all commas from both the price and description fields.
This code is simply a proof-of-concept to show how I solved a problem. If you know of a better way to go about this, please let me know! Hopefully posting this snippet will save someone the time I spent figuring it out.
Show me the errors!
It took me forever to figure out why the hell including a specific class file in one of my PHP scripts was causing the script to output nothing -- besides a blank white page. I finally figured out that PHP must be hiding errors and as soon as I added the following line to the top of my script, the error was obvious (a single character error, no doubt):
ini_set('display_errors', '1');
I was testing on a webhost I had never used before, so I wrongly assumed it was a problem with my code causing the blank output.
Verizon's Ultimate Call Forwarding service allows you to remotely enable/disable call forwarding, as well as change the number to which calls will be forwarded. When you call the automated system to activate call forwarding, there are several other options you can select, such as "Forward after no answer" and "Forward when busy". Those features are extras, for which you need to pay an additional monthly fee. The only feature enabled on account I was configuring is the basic call forwarding, which explicitly forwards all calls. Why then, am I able to select, configure, and enable the other features?
"To enable Forward after no answer, press 1"
"1"
"Please enter the number you wish to forward your calls to"
"617-959-xxxx"
"Please hold while we process your request..."
"Please hold while we process your request..."
"Please hold while we process your request..."
"Forward after no answer has been enabled."
No it hasn't! The damn automated system says its been enabled, when in fact configuring and enabling this feature does absolutely nothing! So much for an intelligent system. It should tell me I don't have that feature enabled, not allow me to configure and enable it.
Link Action plugin for slGrid
There was recently a plugin system added to slGrid, which is great because I recently found the need for a plugin that creates a link around specific cell content and decided to write one.
Link Action allows you to create a URL around the contents of a cell using the unique database column ID. It also allows you to pass the target page for the URL and optional URL arguments. If no target page is passed, it defaults to the current page calling the grid.
<?php
/*
* Example usage:
* $_SESSION["grid"]->SetPlugin("Full_Name", "link_action", array("target" => "users.php", "extra_args" => "&action=edit"));
*
* Assuming the database column ID is 24, and the Full_Name is Raam Dev, here is what the cell would contain:
* Raam Dev
*/
require_once('class.plugin.php');
class link_action_Plugin extends Grid_Plugin
{
function introspect()
{
return(array(
"name" => "Link Action",
"description" => "Creates a URL to call an action using the unique database column ID",
"author" => "Raam Dev ",
"version" => "1.0"
));
}
function generateContent($cell, $args)
{
if(empty($args["target"])){
$args["target"] = $PHP_SELF;
}
if(empty($args["extra_args"])){
$args["extra_args"] = "";
}
return("$cell");
}
}
?>
Project Magnolia
As I mentioned a few days ago, Thea and I are starting a new project together. We'll be using PHP & MySQL on the backend and CSS, XHTML, & AJAX on the front end. Exact project goals have not yet been defined, however we already have a good idea what Magnolia will be: A retail store that allows easy category and item management, while providing the most common tools to serve customers. It would probably make more sense to make use of an open-source shopping cart, however we're both doing this as a learning process and to build project organization skills.
I've created a wiki for the project to help with documentation and development. You can check it out here. I've decided to make the wiki public, as I can't imagine there will be any confidential information added to it. Since the wiki is open to the public, feel free to add your own feature requests to the Feature Requests section of the wiki.
A sore body and a new collaboration
I am incredibly sore from Monday and Tuesdays workouts. Ravi wanted to do arms on Tuesday, so we did workout C instead of workout B. That was probably a bad idea, because it didn't give my chest or arm muscles enough time to recover from the previous day's workout. I'm mostly feeling it in my triceps and obliques -- when I lift my arms over my head.
I've been going over Thea's place on Wednesday nights and tutoring him in PHP programming. The past few sessions haven't been very productive, but thats because I had to get his programming environment setup properly. I installed XAMPP and Eclipse (with the PHP plugin). We decided today that we're going to work on a project together; a web retail store which will allow Wholesale Floral Corp to sell discontinued items to the public. Building this application together will be excellent experience for the both of us. We're going to use the Smarty PHP template engine and stick to Object-Oriented programming as much as possible. To collaborate our development work we're going to use my home CVS server.
PHP & MSSQL Difficulties
I managed to finish a couple of small programming tasks this week that have been on my "todo" list for quite some time. I finally got around to updating the Victoria's Garden Registration Request pages so that they now automatically send email notifications to the customers with their login and password, a task which previously had to be done manually. I took a peek at the victoriasgardenonline.com database today and I was surprised to find a total of over 5,000 records across three different tables.
Now I need to figure out how I can write a couple of utilities using PHP to connect to the MSSQL database on the server. This should be simple. Install PHP on the server, which is already running an IIS web server, and when write the PHP to connect to the local MSSQL database. Well, I was unable to successfully install PHP on the Windows 2000 server, and I am limited in how much I can do because it's a production server and I don't want to screw around with it too much. I would much rather run a second web server using Apache on my Linux box, which is running on the same LAN. I would then need to setup a connection between the Linux server and the MSSQL database on the Win2k Server. Again, I tried this but ran into a few problems. I'll hopefully be able to tackle it again this weekend.
Having Fun with SQL (not)
I was up until 6:00am yesterday morning working on a project for Aerva. I wrote the longest SQL query I've ever written. Here's what it looks like:
[sql]
SELECT ac_users.*, ac_users2customers.*, ac_users2users.*,
customers.*, users.user_id, users.username
FROM ac_users, ac_users2customers, ac_users2users, customers, users
WHERE ac_users2customers.customer_id = '$this->custid'
AND ac_users2users.user_id = '$this->userid'
AND ac_users2customers.ac_user_id = ac_users2users.ac_user_id
AND customers.customer_id = ac_users2customers.customer_id
AND users.user_id = ac_users2users.user_id
AND customers.login_id = users.username
OR ac_users2users.user_id = '$this->userid'
AND ac_users2users.ac_user_id = ac_users.ac_user_id
AND ac_users2customers.ac_user_id = ac_users.ac_user_id
AND customers.customer_id = ac_users2customers.customer_id
AND users.user_id = ac_users2users.user_id
OR ac_users2customers.customer_id = '$this->custid'
AND customers.customer_id = '$this->custid'
AND ac_users2users.ac_user_id = ac_users2customers.ac_user_id
AND ac_users.ac_user_id = ac_users2users.ac_user_id
AND users.user_id = ac_users2users.user_id
AND users.username = customers.login_id
ORDER BY ac_users.first_name;
[/sql]
Those of you who are familiar with SQL might notice some of this is redundant and unnecessary. I know. Right now I don't care; I just need it to work. What does this SQL query do? It selects all users from the ac_users table, with a few conditions. I will attempt (at least partly) to explain what it does in English:
ac_users should only be seen by users who have the ac_user assigned to them (in ac_users2users) or if the company the user belongs to has a login_id that matches the username of another user who has been assigned to the ac_user (again, in ac_users2users).