
I spent this past weekend learning a new language. Not a spoken language, but a programming language called Python. It was incredibly rewarding and it’s hard to believe that I almost paid someone to take that opportunity away.
A few weeks ago I came across a traveling programmer who had written some software to show a map of his travels on an embedded Google Map. He included a drop-down that allowed the selection of different maps, each map representing a different period of travel in his life.
After being thoroughly impressed—and perhaps a little bit jealous—by his extensive travels and the simplicity by which he displayed all this data, I began to envision how I could do something similar on my own website.
His software was fairly straightforward: It looked at the contents of several Google Earth KML files, parsed the map data inside them, and then displayed that data on an embeddable Google Map.
Straightforward? Perhaps. But I didn’t even know what KML files were, let alone how to use Google Earth. The last time I played around with Google Earth was years ago. I had no idea how to create maps with it.
But I wasn’t going to let that stop me.
I foresee myself traveling for years to come and I’ve been looking for a good way to track and display my travels for awhile now. I’m currently using the TravelMap plugin on my map page, but it has limited features and doesn’t scale for my nomadic lifestyle. This Google Earth solution seemed elegant, practical, and scalable.
So I downloaded Google Earth and learned how to create lines and points. I watched tutorial videos on YouTube and read documentation. I exported one of the test maps to a KML file and opened it in a text editor to learn about its format.
I discovered that KML files were simply XML files (very similar to HTML). The locations of the points that I added in Google Earth were identified using its GPS coordinates; the lines that I drew between two points were represented by a series of coordinates: start-coordinates, end-coordinates, start-coordinates, end-coordinates, and so on.
With my newly acquired knowledge I set out building several Google Earth maps, each representing all my travels for the past two years, starting with my trip to India in 2010 and ending with my present location in Australia in 2012.
It was around this point where I began to think about what the process of updating my current location with this system would look like on a day-to-day or week-to-week basis.
I realized it would require opening Google Earth on my computer, editing the map with my new travels and adding new points and new lines, then exporting the file to KML and uploading it to the web server.
That seemed like a lot of work, especially when I was already recording my travels to some degree using geotagging on social networks like Twitter and Foursquare.
I’m very suspicious of repetitive things when it comes to my time. (It all started when I calculated how much of my life each year was being spent simply looking at various notifications on my computer: 15 hours! I no longer use notifications for anything.) If I’m already recording my location online, why should I spend time recording it again in Google Earth?
How could I automatically update the Google Earth KML file with my latest location without spending any additional time?
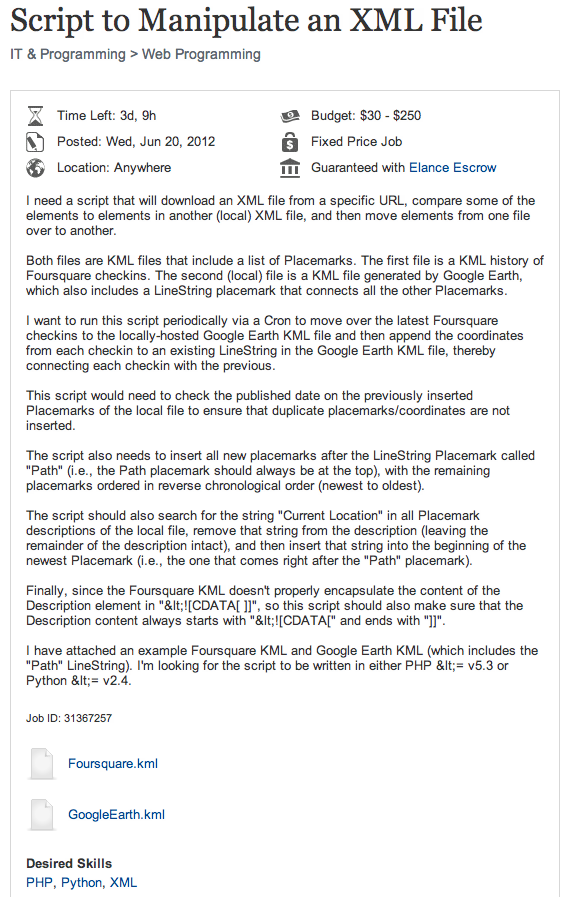
After a bit of research, I discovered that Foursquare provides a KML feed for all my check-in data. So, I just needed to create a program that would automate copying the data from one KML file to the other and then updating the path line to show that I traveled from the old check-in to the new check-in.
With my limited knowledge of programming languages, I knew that Python was the best language for this job. The problem was, I knew practically nothing about Python. I was a PHP programmer and I knew that solving this problem with PHP would be both messy and time-consuming.
At this point I’d already spent a lot of time learning about KML files and creating maps in Google Earth. The thought of learning a whole new programming language just to get a travel map on my site was pushing the limits of what I expected to invest in this project in terms of time.
Wouldn’t it be easier to just hire someone else to do this final part?
Never before had I hired someone to write a program for me, but for the first time I found myself taking the thought seriously. Was I getting lazy? Was this laziness the result of being able to afford to hire someone?
I posted the job on Elance with a maximum budget of $250— that’s what this program was worth to me. Within a few hours I began receiving bids, but with each bid I felt myself more and more disinterested with this idea.
Why was I paying someone to take away my opportunity to learn and grow?
That’s when I realized something important: It wasn’t that I was being lazy. It’s that I wanted to pay someone to take away the discomfort of learning and growing.
That one realization changed my whole thinking and instead of succumbing to the discomfort of learning something new, I decided to push into the discomfort and find out what’s on the other side.
On Friday night I found a free Python tutorial online and began learning. I started with the very basics and ignored what I already knew about programming. I completed every exercise, from the very basic to the more advanced.
At first it was repetitive and boring, but as the hours passed I found myself muttering over and over, “that’s interesting”, every time I learned a new concept or understood how something worked.
This learning and exploration became so fun that I spent nearly the entire weekend indoors, peeling myself away from the computer only to eat, fulfill my running commitment, and watch the sunset.
By Sunday morning I began exploring beyond the Python tutorial and started searching the Internet for examples of using Python to handle XML files. There were very few examples specific to KML files and I couldn’t find anything that did what I wanted, but I continued experimenting.
By that evening I had finished a 248-line program in Python that did exactly what I wanted. It’s certainly not the prettiest code but the sense of empowerment and elation that I experienced upon finishing it was worth far more than $250.
The lesson? When it comes to spending time or spending money, always spend the time if you’ll learn something that will save you both money and time in the long-run.
And more importantly, when it comes to learning new things, don’t pay someone to take away the discomfort for you: lean into that discomfort.
On the other side of that discomfort exists a world where you live with more knowledge and understanding than the present version of yourself. It may be hard to imagine that world right now, but push through the discomfort and you’ll get there.
I haven’t finished integrating the new travel map into my site, but here’s a working sneak peak of the Journey Map.
{kind=link}